在我们之前的文章中,我们演示了如何使用ChatGPT API构建一个AI聊天机器人并分配一个角色以个性化它。但是,如果您想要在自己的数据上训练AI怎么办?例如,您可能有一本书、财务数据或大量的数据库,希望能轻松地进行搜索。在本文中,我们为您带来了一个易于跟随的教程,介绍如何使用LangChain和ChatGPT API训练具有自定义知识库的AI聊天机器人。我们正在部署LangChain、GPT Index以及其他强大的库来训练AI聊天机器人,使用OpenAI的大型语言模型(LLM)。因此,在这个注记上,让我们看看如何使用您自己的数据集来训练和创建一个AI聊天机器人。
目录
- 设置软件环境以训练AI聊天机器人
- 安装Python和Pip
- 安装OpenAI、GPT Index、PyPDF2和Gradio库
- 下载代码编辑器
- 免费获取OpenAI API密钥
- 使用自定义知识库训练和创建AI聊天机器人
- 添加要训练AI聊天机器人的文档
- 准备好代码
- 使用自定义知识库创建ChatGPT AI机器人
- 管理自定义AI聊天机器人
在您使用自己的数据训练AI之前,请注意以下要点
- 您可以在任何平台上训练AI聊天机器人,包括Windows、macOS、Linux或ChromeOS。在本文中,我使用的是Windows 11,但其他平台的步骤几乎相同。
- 本指南适用于普通用户,指令用简单的语言解释。因此,即使您对计算机有一些了解但不知道如何编程,也可以轻松地在几分钟内训练和创建一个问答式AI聊天机器人。如果您之前关注过我们的ChatGPT机器人文章,那么理解过程将更加容易。
- 由于我们将基于自己的数据训练AI聊天机器人,建议使用性能良好的计算机,配备良好的CPU和GPU。但是,您可以在测试目的中使用任何低端计算机,它将无任何问题运行。我使用了一台Chromebook来训练AI模型,使用了一本拥有100页(~100MB)的书。但是,如果您想要训练包含成千上万页数据的大型数据集,强烈建议使用一台强大的计算机。
- 最后,数据集应该是英文的,以获得最佳结果,但根据OpenAI的说法,它也可以与流行的国际语言(如法语、西班牙语、德语等)一起使用。因此,请尝试在您自己的语言中使用它。
设置软件环境以训练AI聊天机器人
安装Python和Pip
- 首先,您需要按照我们提供的链接上的指南,在计算机上安装Python和Pip。在安装过程中,请确保在“将Python.exe添加到PATH”选项上启用复选框。

- 要检查Python是否正确安装,请在计算机上打开终端。一旦在此处,请逐个运行下面的命令,并输出它们的版本号。在Linux和macOS上,您必须从现在开始使用
python3,而不是python。
python –version
pip –version
- 运行下面的命令来更新Pip到最新版本。
python -m pip install -U pip
安装OpenAI、GPT Index、PyPDF2和Gradio库
- 打开终端并运行下面的命令来安装OpenAI库。
pip install openai
- 接下来,让我们安装GPT Index。
pip install gpt_index==0.4.24
- 现在,通过运行下面的命令来安装Langchain。
pip install langchain==0.0.148
- 之后,安装PyPDF2和PyCryptodome以解析PDF文件。
pip install PyPDF2
pip install PyCryptodome
下载代码编辑器
最后,我们需要一个代码编辑器来编辑一些代码。在Windows上,我建议使用Notepad++(下载)。只需通过附带的链接下载并安装程序。如果您熟悉功能强大的IDE,也可以在任何平台上使用VS Code。除了VS Code,您还可以在macOS和Linux上安装Sublime Text(下载)。
对于ChromeOS,您可以使用优秀的Caret应用程序(下载)来编辑代码。我们几乎已经完成了设置软件环境的工作,现在是时候获取OpenAI API密钥了。
免费获取OpenAI API密钥
- 前往OpenAI的网站(访问)并登录。接下来,单击“创建新的秘密密钥”并复制API密钥。请注意,以后无法复制或查看整个API密钥。因此,建议将API密钥复制并粘贴到Notepad文件中以备将来使用。

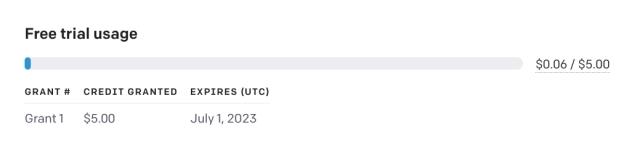
- 接下来,前往platform.openai.com/account/usage并检查是否有足够的余额。如果您已经用光了所有的免费信用,需要为您的OpenAI账户添加支付方式。
使用自定义知识库训练和创建AI聊天机器人
添加要训练AI聊天机器人的文档
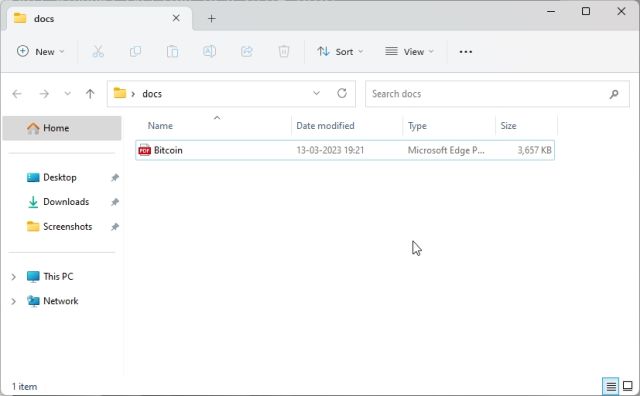
- 首先,在一个可访问的位置,如桌面上,创建一个名为
docs的新文件夹。您也可以根据自己的喜好选择其他位置。但请保持文件夹名称为docs。

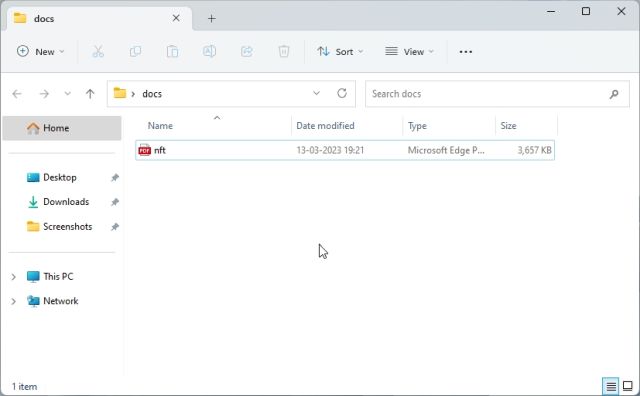
- 接下来,将用于训练的文档移动到“docs”文件夹中。您可以添加多个文本或PDF文件(甚至是扫描文件)。如果您在Excel中有一个大型表格,您可以将其导入为CSV或PDF文件,然后将其添加到“docs”文件夹中。您还可以添加SQL数据库文件,如这个Langchain AI推文中所解释的。除了上述提到的文件格式,我没有尝试其他文件格式,但您可以自行尝试和检查。对于本文,我添加了一个PDF格式的关于NFT的文章。
注意:如果您有一个大型文档,处理数据将需要更长的时间,具体取决于您的CPU和GPU。此外,它将迅速使用您的免费OpenAI令牌。因此,在开始时,请使用一个较小的文档(30-50页或< 100MB的文件),以了解流程。
准备好代码
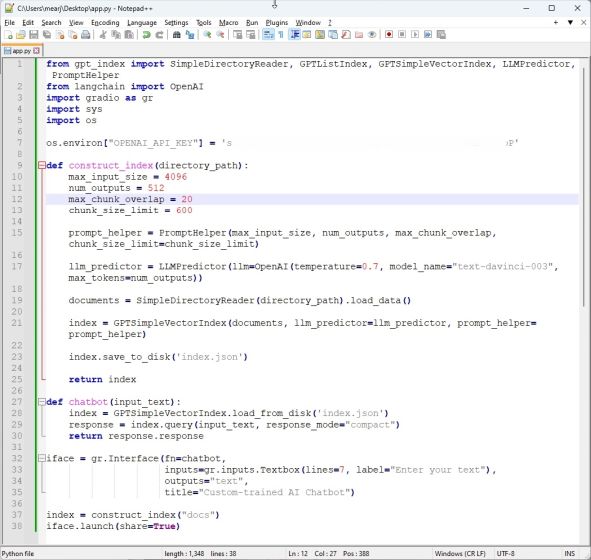
- 现在,打开Sublime Text等代码编辑器,或者启动Notepad++,并粘贴以下代码。再次,我得到了Google Colab上的armrrs的巨大帮助,并调整了代码以使其与PDF文件兼容,并在顶部创建了一个Gradio界面。
from gpt_index import SimpleDirectoryReader, GPTListIndex, GPTSimpleVectorIndex, LLMPredictor, PromptHelper
from langchain.chat_models import ChatOpenAI
import gradio as gr
import sys
import os
os.environ["OPENAI_API_KEY"] = 'Your API Key'
def construct_index(directory_path):
max_input_size = 4096
num_outputs = 512
max_chunk_overlap = 20
chunk_size_limit = 600
prompt_helper = PromptHelper(max_input_size, num_outputs, max_chunk_overlap, chunk_size_limit=chunk_size_limit)
llm_predictor = LLMPredictor(llm=ChatOpenAI(temperature=0.7, model_name="gpt-3.5-turbo", max_tokens=num_outputs))
documents = SimpleDirectoryReader(directory_path).load_data()
index = GPTSimpleVectorIndex(documents, llm_predictor=llm_predictor, prompt_helper=prompt_helper)
index.save_to_disk('index.json')
return index
def chatbot(input_text):
index = GPTSimpleVectorIndex.load_from_disk('index.json')
response = index.query(input_text, response_mode="compact")
return response.response
iface = gr.Interface(fn=chatbot,
inputs=gr.components.Textbox(lines=7, label="Enter your text"),
outputs="text",
title="Custom-trained AI Chatbot")
index = construct_index("docs")
iface.launch(share=True)
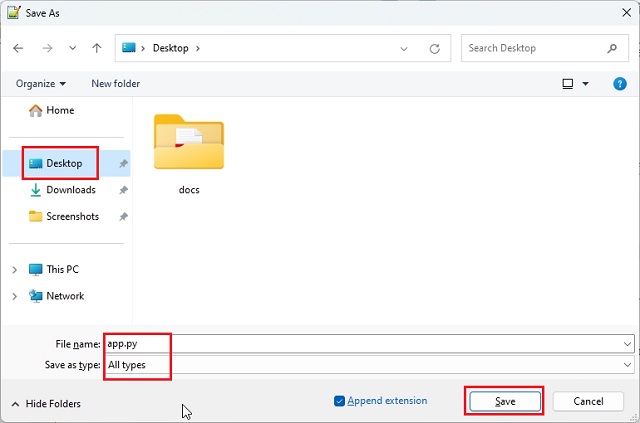
- 接下来,单击顶部菜单中的“文件”,然后选择“另存为…”。然后,设置文件名为
app.py,并将“另存为类型”更改为“所有类型”。然后,将文件保存到您创建“docs”文件夹的位置(在我这里,是桌面)。
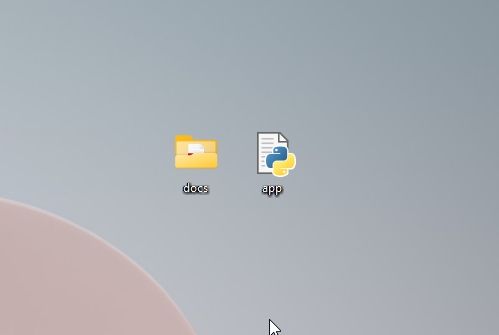
- 确保“docs”文件夹和“app.py”位于相同的位置,如下面的截图所示。”app.py”文件将位于”docs”文件夹之外,而不是内部。
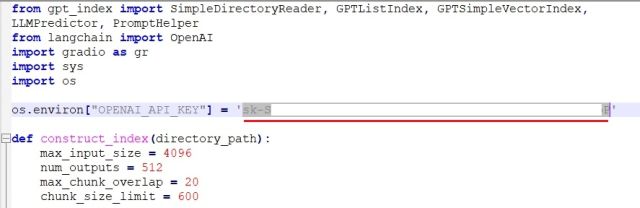
- 回到Notepad++中的代码。在这里,将
Your API Key替换为您在OpenAI网站上生成的API密钥。
- 最后,按“Ctrl + S”保存代码。现在您已经准备好运行代码。
使用自定义知识库创建ChatGPT AI机器人
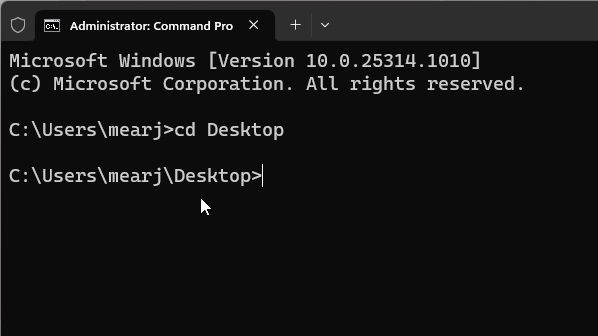
- 首先,打开终端,并运行以下命令来进入桌面。这是我保存“docs”文件夹和“app.py”文件的地方。
cd Desktop
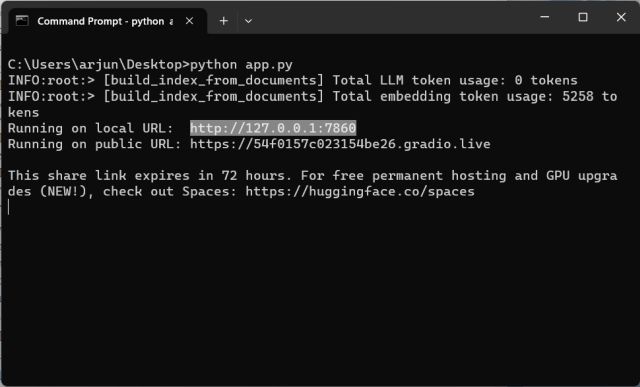
- 现在,运行以下命令。
python app.py

- 它将使用OpenAI LLM模型开始索引文档。根据文件大小,处理文档将需要一些时间。完成后,桌面上将创建一个“index.json”文件。如果终端没有显示任何输出,请不要担心,它可能仍在处理数据。就您的信息而言,处理一个30MB的文档大约需要10秒。

- 一旦LLM处理完数据,您将找到一个本地URL。复制它。
- 现在,将复制的URL粘贴到Web浏览器中,然后就完成了。您的自定义训练的ChatGPT AI聊天机器人已经准备好了。要开始,您可以问AI聊天机器人文档是关于什么的。

- 您可以提出进一步的问题,ChatGPT机器人将根据您提供给AI的数据进行回答。这就是您如何使用自己的数据集构建自定义训练的AI聊天机器人。您现在可以基于任何类型的信息训练和创建AI聊天机器人。
管理自定义AI聊天机器人
- 您可以复制公共URL并与朋友和家人共享。链接将在72小时内有效,但由于服务器实例正在您的计算机上运行,因此您还需要保持计算机开启。
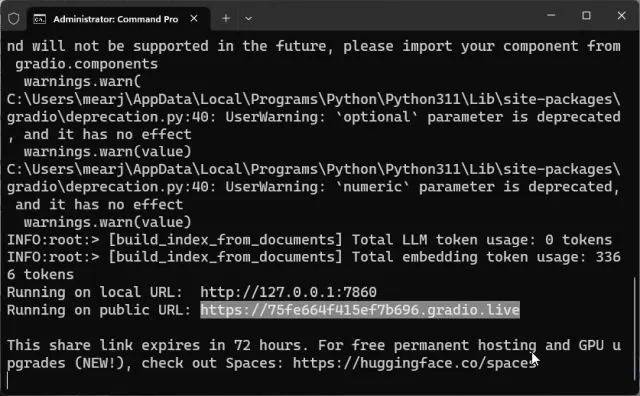
- 要停止自定义训练的AI聊天机器人,请在终端窗口中按“Ctrl + C”。如果不起作用,请再次按“Ctrl + C”。
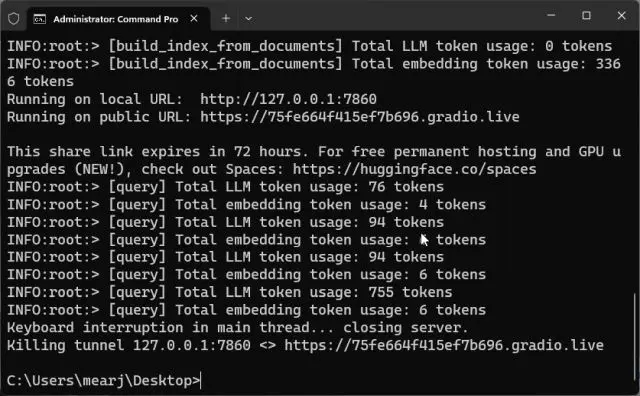
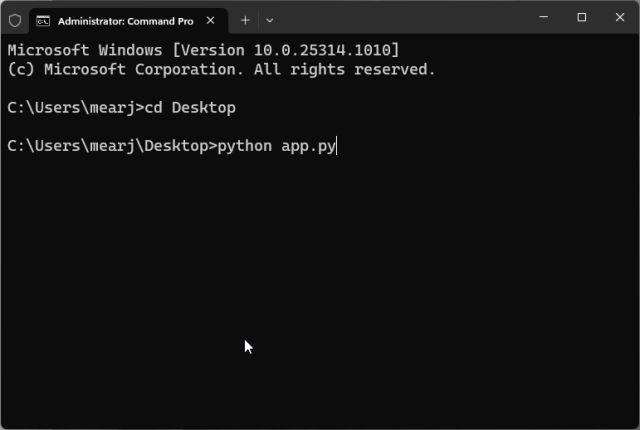
- 要重新启动AI聊天机器人服务器,只需再次进入桌面位置并运行以下命令。请注意,本地URL将保持不变,但每次服务器重新启动后,公共URL都会更改。
python app.py
- 如果要使用新数据来训练AI聊天机器人,请删除“docs”文件夹中的文件并添加新文件。您也可以添加多个文件,但请确保添加干净的数据以获得连贯的响应。
这就是使用自定义知识库训练和创建AI聊天机器人的完整过程。希望这篇文章对您有所帮助,您现在可以探索更多有趣的内容并与您的AI聊天机器人互动。不仅如此,您还可以将其用于个人或商业用途,例如客户支持、知识库、文档检索等。
请注意,OpenAI可能会根据其政策更改API的使用方式和价格。在开始使用API之前,建议查看OpenAI的最新政策和价格信息,以确保您的使用方式是符合要求的。
这就是我们的教程。如果您有任何疑问或反馈,请在下面的评论中告诉我们。